
Harness Engineering. The Real Skill Behind AI-Assisted Development.

In my last newsletter I argued that architectural judgment stays human. AI agents generate code, but we as architects decide which trade-offs to make and why. So how do you actually work with AI agents in a way that leverages your judgment?
I’ve found that the biggest lever is the environment you build around the agent. The constraints, feedback loops, and evaluation criteria that shape what the agent produces. Birgitta Böckeler writes about this process (called harness engineering) in detail1.
The harness
A harness is everything surrounding the agent. What it can see, what feedback it gets, what constraints it operates under. You define what “good” looks like, and the harness tells the agent when it’s not there yet.
Think of reconciliation loops in Kubernetes. You declare the target state. A reconciler works toward it. You don’t micromanage the steps. You define what “good” looks like and let the system figure out how to get there.
Harness engineering works the same way. You encode your judgment into the harness and the agent reconciles toward it.
Fitness functions as a harness
I recently built the first version of an AI-native architectural analysis tool. I started by building the evaluation layer.
First, I defined fitness functions. These encode my architectural judgment about what “good” means for this specific system. One example: the tool sends a text summary of the codebase to an LLM, so I defined a token cost fitness function. It measures the token count of the generated summary and fails if it exceeds 12,000 tokens. That threshold encodes a judgment: the summary must fit in a single LLM context window with room for the analysis prompt. Other fitness functions cover findings quality, schema conformance, and parser coverage.
Then I built a dashboard to compare approaches against these functions.
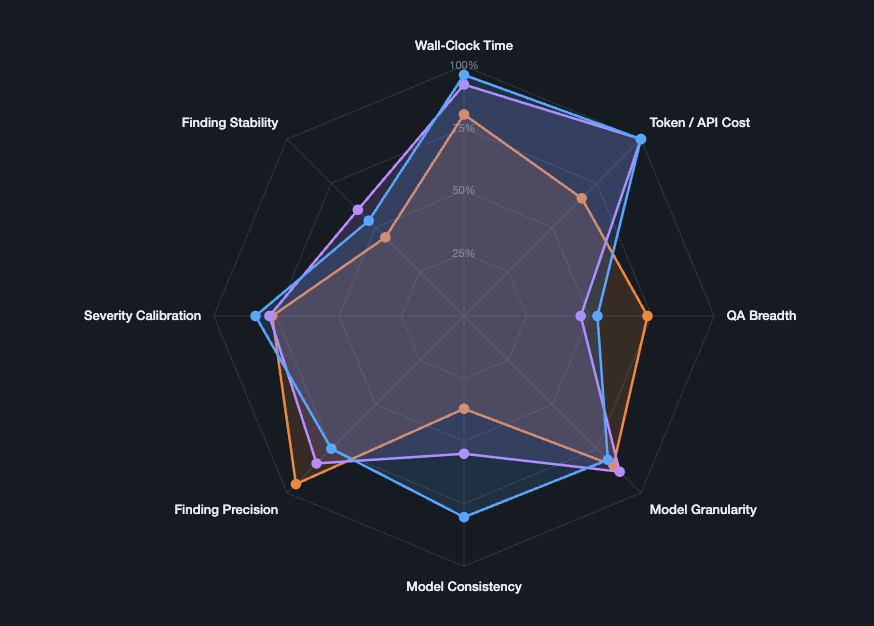
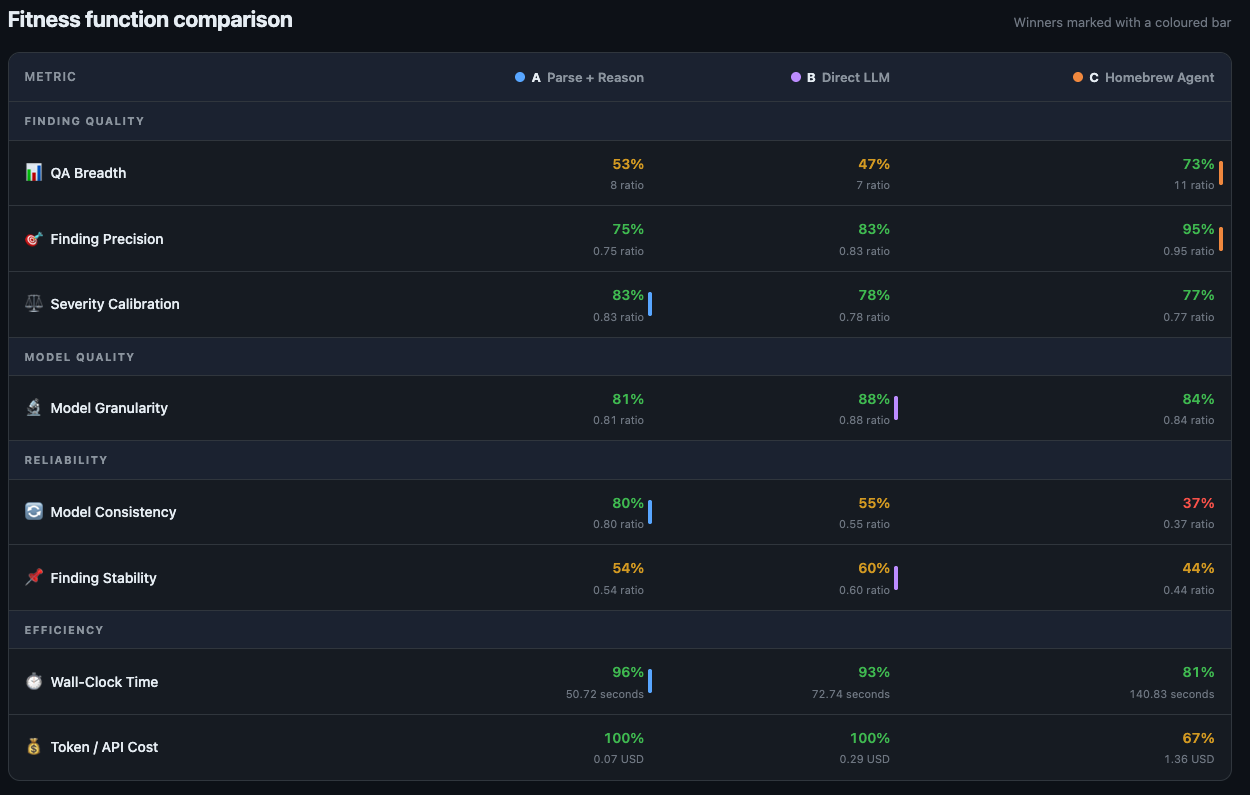
Only then did I let AI agents implement solutions. The harness was already in place.
The dashboard lets you compare solutions against your judgment. When an approach scores poorly on a fitness function, you see it immediately.
Fitness Functions are target state contracts.
When you put your architectural judgment into the evaluation layer, every AI-generated solution gets measured against it automatically. You can fan out multiple agents exploring different approaches and let the harness pick the winner.
The judgment is still yours. You chose the fitness functions, you decided what “good” looks like. Now that judgment is encoded in something durable and repeatable.
This comes with a risk. Fitness functions can encode the wrong judgment. If you optimize for token cost alone, the agent will produce summaries that are short but miss critical architectural details. The harness is only as good as the judgment you put into it. That’s why you need multiple fitness functions that balance each other, and why you should revisit them as you learn more about your problem.
Build the evaluation before the implementation. Let the harness carry your judgment. Evaluate constantly.
Böckeler, B. (2025). Harness Engineering. martinfowler.com