
Network Communication And Leaky Abstractions
Synchronous communication in distributed systems is a leaky abstraction. Discover how asynchronous messaging builds resilient systems that decouple services from unpredictable network failures.

Method and function calls are simple, right? You call a function by its name and pass in parameters, then the function returns - everything happens in a clearly defined order. However, things get more complicated in distributed systems. Imagine Service A calling Service B synchronously and directly over a network:
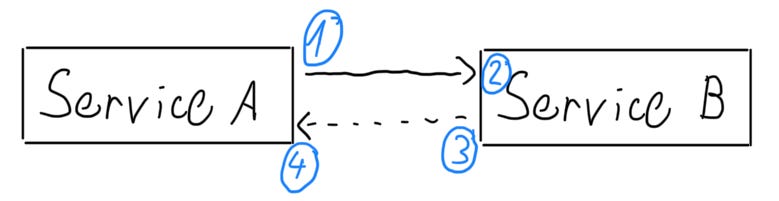
Service A sends a request (1) and then waits for Service B’s response. Service B processes the request (2) and sends back a response (3). Then Service A receives the response and resumes (4). In a local call, the CPU jumps directly to the function’s memory address. Over a network, though, messages travel over unreliable links. They might be delayed, dropped, or even lost if Service B is down.
Synchronous network calls mask network issues by mimicking local procedure calls. This is a leaky abstraction: the network’s unreliability eventually shows up in your code. If Service B is unavailable or slow, Service A must handle retries, timeouts, or implement circuit breakers. This adds complexity and creates tight runtime coupling between services.
Instead, asynchronous and indirect communication makes network properties explicit. With asynchronous communication, Service A sends a request and continues processing other tasks, handling the response later through a callback. Indirect communication means that neither the caller nor the receiver is directly connected; they interact through an intermediary, such as a message queue or append-only storage.
To approach why the networks nature is more explicit in this sort of communication, let’s look at two examples and list out the kinds of assumptions the calling service makes about the underlying network. This is a proxy for the degree of coupling, since it shows how much the calling service needs to now about the network and the called service.
The first example is synchronous and direct communication between services. Like in the figure above, let’s assume that Service A contacts Service B. It has the following assumption about the communication with Service B:
“I know that Service B exists”
“I know where Service B is located so I can directly contact it”
“I will get a response from Service B in time”
If any of these assumptions fail, Service A must deal with the error. Service B is not available? Service A needs to retry the request. Service B takes a long time to respond? Service A needs to track a timeout. Either way, there is a lot of burden on Service A to handle fallback mechanisms. Network failures leak into the implementation of Service A, increasing its complexity and its coupling to Service B.
Now, let’s look at asynchronous and indirect communication, more specifically a request/reply pattern. This discussion similarly applies to other forms of messaging, like publish/subscribe or event mechanisms.
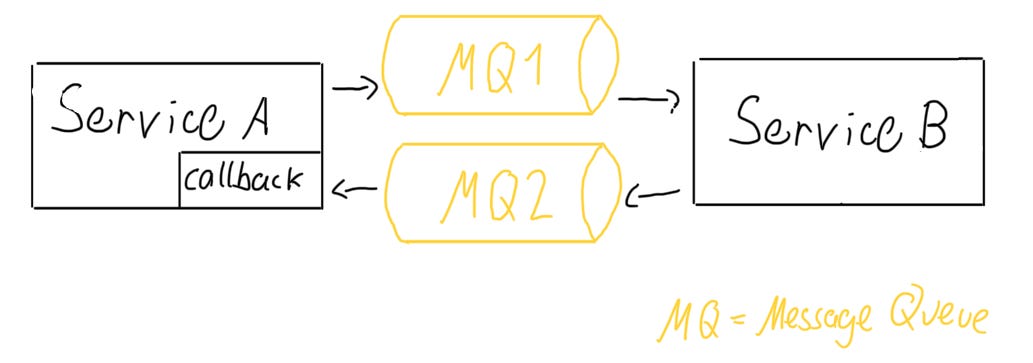
Here are the assumptions that Service A has about the communication with Service B:
“I send a message to Message Queue 1 and someone will handle it.”
“Eventually, I will receive a response on Message Queue 2 which my internal callback will handle.”
There are much less assumptions which leak failure modes into the implementation of Service A. Since it is already implemented in a way where it handles responses eventually, the unreliability of the network is already baked into the design of the communication.
Using this form of communication forces you to design for failure. It includes all failure modes of network connections as first-class in the design of the communication protocol. Designing a service that sends requests and handles responses asynchronously means that you are forced to design the service in a way where responses come back at an arbitrary time and the service should be able to handle it. This mitigates potential network failures like increased latency or dropped connections and puts solutions to those failure modes in the design of the communication.
Another interesting example where asynchronous communication shines is that it helps to decouple individual services over the dimension of time.
(De-)coupling in Time
Think about cooking soup. Some tasks, like cutting onions and heating water, can happen simultaneously, but other steps must occur in a strict order, like adding ingredients only after preparation is complete. Similarly, software systems are often built in a way where certain parts/routines need to be executed before other parts can be executed. We call this temporal coupling. An example I witnessed recently was a data pipeline that stored data in a shared database and another pipeline read out of that shared database. Both pipelines were coupled temporally because one pipeline needed to execute before the other one.
Similarly, synchronous communication over networks always leads to temporal coupling. When Service A call Service B, it is dependent on the latter’s timing and availability. If Service B is down or responds slowly, due to the synchronous call’s blocking nature, Service A has to wait and delay potentially waiting upstream services.
The goal should be to design distributed systems where individual services can operate independently over time, instead of coupling them by relying on certain execution orders. Using asynchronous communication helps here. As I have mentioned above, designing systems in this way better reflects the reality of potentially unreliable network communication.
Let’s look at an example. Say you have an order service which checks an inventory service to check for availability of products before confirming the order to the user. The order service looks like this internally:
function processOrder(order) {
// Synchronous call: wait for the response
const inventoryStatus = inventoryService.checkAvailability(order.items);
if (inventoryStatus.available) {
console.log('Inventory available, processing order.');
// Continue processing the order
} else {
console.log('Item out-of-stock, notifying customer.');
// Handle out-of-stock scenario
}
}With asynchronous communication, we again use an intermediary. Let’s implement two message queues in this example, one for sending requests and one for responses:
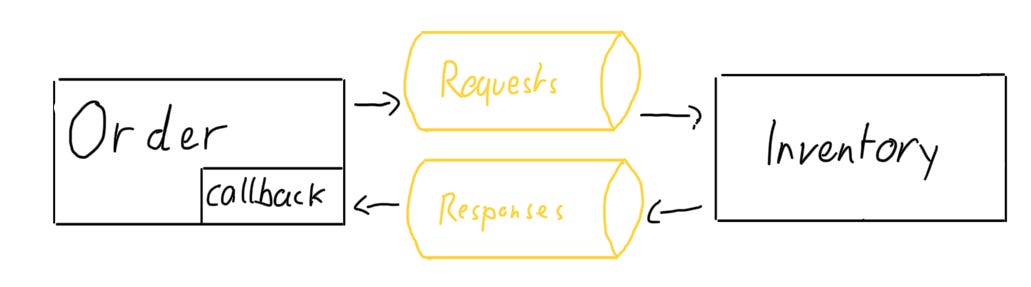
The order service uses a callback which is being invoked as soon as a response is sent over the responding message queue:
function processOrder(order) {
// Asynchronous call: continue processing without waiting
inventoryService.checkAvailabilityAsync(order.items, (inventoryStatus) => {
if (inventoryStatus.available) {
console.log('Inventory available, processing order.');
// Continue processing the order
} else {
console.log('Item out-of-stock, notifying customer.');
// Handle out-of-stock scenario
}
});
// Other independent tasks can be performed here without waiting
console.log('Order received; processing will continue once inventory is confirmed.');
}The second example has lower temporal coupling since the order service has no expectations about the availability of the inventory service. All it is concerned about is sending requests to a message queue and receiving responses from another one which invokes its callback.
Drawbacks of Asynchronous Communication
While this post advocates for asynchronous communication, it’s important to note that it comes with its own challenges—such as managing message ordering, debugging flows, and handling eventual consistency.
I don’t want to convince you to use asynchronous and indirect communication in every case but to use its strength in making network properties more explicit in the system’s architecture. One rule of thumb I have had good experience with is to incorporate domain boundaries: using asynchronous, indirect communication when communicating across bounded contexts (usually event-driven communication) but being more open to synchronous, direct communication within bounded contexts. If you want to know more about bounded contexts, check out my post “A Case Against 'One Model to Rule Them All’”.
By designing with asynchronous, indirect communication, you build systems that naturally account for network unreliability, reduce tight coupling, and allow services to operate independently—making your distributed architecture more robust, scalable and adaptable.