
The Hidden Costs of Sharing: When to Break the DRY Principle

When I started building software, I learned about a prevalent principle: Don’t Repeat Yourself (or DRY). It advocates avoiding redundancy and duplication. Following this principle, developers extract duplicate code into separate modules or libraries. Developers also ensure that there is only one place where they store data, a “single point of truth.” When applying DRY, the mantra is to share: share code, share data, and share functionality.
Intuitively, this made sense to me. Why write code twice when you can write it once and have one single spot to maintain it? Why store data redundantly when you can have one place to update it?
Over the years, however, I discovered that it is more intricate, and there are drawbacks to this approach. Before exploring when it is a good idea to repeat yourself, let’s discuss a few examples of things software modules often share.
Data Model
When two modules read from and write to the same database objects (like tables, documents, nodes, or items, depending on the database technology in use), they share the same data model. They often communicate by writing items to a shared object, with one module writing and the other reading. This pattern usually appears in monolithic applications where modules operate on the same data schema.
The resulting coupling usually hinders the modules' ability to evolve independently. In the figure below, if different teams are responsible for the two modules and one team needs to adapt the shared data model, the other team must also adjust its code.

Contrary to DRY, microservices usually promote redundant data storage. Each microservice stores its data and does not share it with others.
Functional Code
Several modules might rely on some common functionality related to their domain. These are often algorithms used across modules, e.g., tax calculation in an employee management system. It might be obvious to extract this common functionality into its own module (or a shared library for multiple repositories). Following this approach, we would arrive at something like this:

The shared functionality is neatly separated and encapsulated in a library. You only have one place to change related functionality. This design, however, comes with trade-offs. In A Case Against 'One Model to Rule Them All', I discussed the issues that arise when multiple bounded contexts depend on a unified model. The same applies here: imagine the functionality within the shared library changes, e.g., new tax regulations in a tax calculation. You'd have to adapt the library, all dependent modules, and most unit and integration tests.
Domain-driven Design describes a pattern for sharing a domain model across contexts: the shared kernel. It involves two bounded contexts agreeing on and sharing a part of their domain model through explicit code sharing.

This type of coupling, like sharing a data model, not only leads to a system that is hard to evolve. This is because multiple bounded contexts need to be involved in changes in the shared modules. It also increases the risk of introducing bugs and unexpected side effects since the changes affect large parts of the system. The system’s domain is a regular subject to change, so these problems arise regularly.
Technical Code
Like functional code, you can extract common technical code into its own module. Potentially, this also causes problems with evolvability, but I evaluate this situation differently. Functional, domain-oriented code tends to change more often than technical code. When functional code in a common module is adapted, all modules usually need to be changed to restore a coherent state of the entire system. This is different from technical code. Sharing, e.g., a logging library, is not the subject of many urgent changes connected to things like deadlines. Also, versioning reduces coupling. It helps when modules don't need to use the same functionality at the same time, which is often the case with technical code.
Assumptions
A more subtle sharing mechanism is when multiple modules share assumptions about their internal model. Let's look at an example: take a lab result module and patient registration module in a hospital's software system. Both handle patients and have a representation of patients within their internal domain model. Both rely on assumptions, such as every patient having an associated social security number. If the registration suddenly starts admitting patients who pay directly and not via insurance, patients without social security numbers pop up in the system. The assumption about the patient always having a social security number changes. This also affects the lab result module because they'd need to change their internal domain model assumptions about patients.
Situations like this are hard to detect, and errors are hard to debug. Sharing assumptions is not as explicit as sharing code or data. It is not detectable by tools and is often a result of implicit communication and agreements between development teams.
To Share or Not to Share?
When is it a good idea to share? To answer this question, I want to discuss two aspects: cost of duplication and cost of coordination.
Cost of Duplication
Duplicating code has drawbacks. Redundant data, for example, can lead to inconsistencies. Designing a system for eventual consistency is crucial here but adds complexity.
Further, redundant functional code still leads to coupling, but in a more nuanced way. If the domain model behind the shared functionality needs to be adapted, this can affect all modules where the redundant code sits. Like in our example before, we had tax calculation logic. If you add this functionality redundantly and tax laws change, you still must adapt all affected modules. The upside of duplication is that each team can prioritize the changes of their own modules. There is no "big bang" adaptation due to changes in a common module or library.
Cost of Coordination
I described the costs introduced by coordination due to sharing in detail above. What’s essential is that coordination costs depend on two factors.
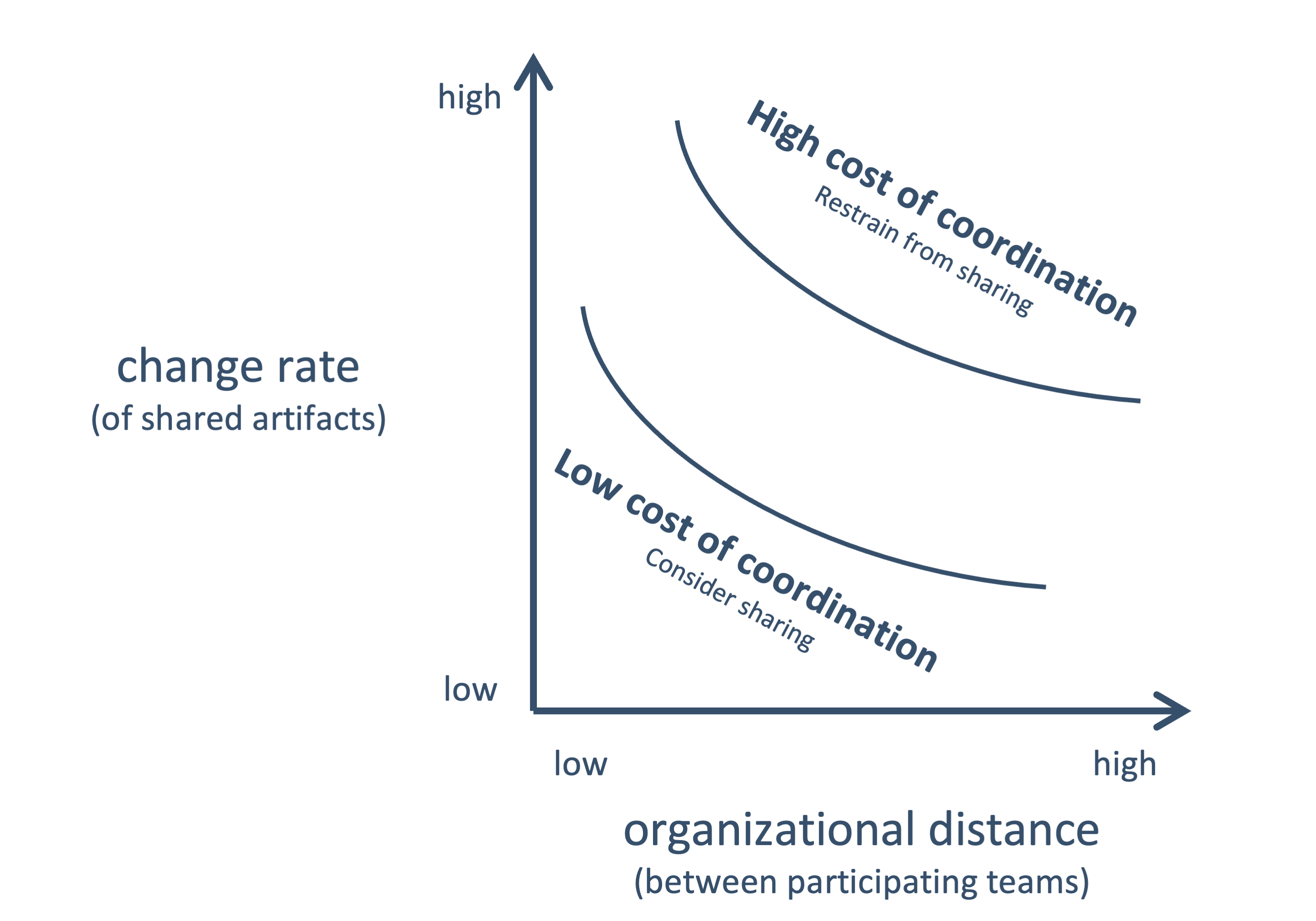
Organizational distance describes how far the participating teams are separated in an organization. Closer organizational distance tends to lessen the drawbacks of coordination.
Imagine a team responsible for three modules. A common module used by all three team modules won't raise coordination efforts much. That's due to the team having tight and daily communication. They can communicate changes efficiently and use continuous integration to ensure that changes in the common module do not lead to unwanted side effects.
Sharing might get complex if teams are split across organizational units and rarely communicate. Since changes to shared code, data, or assumptions are risky, they need close integration and communication. If the teams are too far apart, sharing is error-prone and introduces overhead.
Change rate is the frequency by which the shared elements change. A lower change rate is better for reusability because the modules that use shared artifacts are less volatile. That's why I generally advise being more skeptical about sharing functional code than technical code.
Conclusion
Deciding to share and reuse occurs in several situations. A few examples of shareable artifacts are data models, (functional and technical) code, and assumptions about the domain model. The higher the organizational distance and change rate of those things, the higher the coordination cost becomes, leading to a situation where sharing is generally more unfavorable. Contrarily, reusing is better when shared artifacts don’t change often and affect teams with close organizational distance, leading to lower coordination costs.
Further Reading & References
If you want to read about how Microservices approach the question of sharing, redundancy and coordination, I recommend this popular article by James Lewis and Martin Fowler.
The idea of comparing cost of duplication and cost of coordination was inspired by the book Learning Domain-Driven Design: Aligning Software Architecture and Business Strategy by Vladik Khononov. In Chapter 4, Vladik broadly introduces those two factors in the context of discussing shared kernels.